Since the dawn of the modern computer, data has been a core architectural component. Every system needed an interface to collect and present data, a way to process that data and some place to store it.
As simple as that paradigm may be – or perhaps because of its simplicity – it has persisted throughout the evolution of digital systems from the mainframe to the cloud. We have now, however, entered the era of big data and a time in which competitive advantage goes to those organizations who can most rapidly leverage their data and find insight from it. And that means that the underlying model of how organizations store and manage data must change.
The Data Pipeline Evolution
In the beginning, it was simple: each system stored data in one place for its own use. As systems grew in complexity, however, multiple systems needed that same data. IT organizations, therefore, had to find ways to move data and share it between systems – what is sometimes called a data pipeline.
These original data pipelines were simple and based on the concept of extracting the data from the original system, transforming the data into a format usable by the next system and loading the data into the new system – or extract, transform, and load (ETL).
ETL processes were slow, cumbersome and processed in batch mode, typically at the end of some pre-set period of time. As these data pipelines grew longer and more complex, however, and as the need for the data became more urgent, the traditional ETL approach broke down. This form of data flow is simply too unwieldly for many of today’s needs.
Moving Beyond Storage: iguazio and the Modern Data Pipeline
Organizations built early data pipelines based on the idea of moving data between storage locations where various systems could access that data. The primary purpose of the data was for use in transactional systems of record.
As data, however, has become the chief enabler of both competitive advantage and the customer experience, organizations must now analyze and act upon that data in real-time. This need was the driver behind the creation of iguazio.
iguazio’s goal is to simplify the data pipeline and help organizations move from processing data in batch to being able to uncover real-time insights. It does this by re-envisioning the entire data pipeline paradigm, but it is important to recognize that this is not merely a new approach to storage or data management.
iguazio’s solution is a continuous data insights platform that uses commodity hardware to enable organizations to rapidly ingest, process, and consume data. Architecturally, the company builds a unified real-time database which uses a combination of distributed, virtual, non-volatile memory and dense tiered storage to deliver a single data platform that can dynamically manage both streaming and persistent data structures.
This approach enables organizations to use these continuous insights to guide real-time actions in both transactional and analytical use cases.
Creating Continuous Analytics with a Unified Data Model
The secret to iguazio’s approach is what it calls its Unified Data Model. This proprietary model enables the platform to store and index data once, but then present or query that data via standard APIs as a stream, as file objects, as database records or in almost any way necessary to allow subscribing systems to consume it.
This unified model is protected with ‘fine-grained’ content-aware security. This includes full auditing, end to end authentication and authorization, which enables secure data sharing across business departments or external users. At the same time, this intricate level of control satisfies the most rigorous data compliance needs and helps organizations break through organizational barriers.
Instead of forcing organizations to use a new set of APIs, the platform exposes data through Amazon-compatible streaming and database APIs and also integrates with Hadoop, Spark, and Kubernetes. In this way, applications can consume and manage iguazio’s platform services with self-service and multi-tenant portals deployed either on-premises or in the cloud.
The result is an ability to ingest data once – whether it is streaming or persistent – and then dynamically enrich, analyze, use machine learning, and serve that data, or its derivatives, in real-time to identify and act upon the insights gleaned from it.
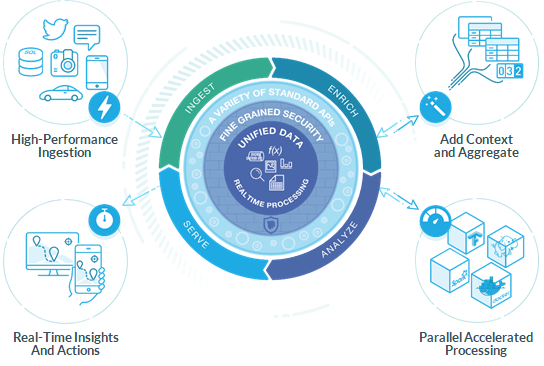
The company calls this capability, continuous data insights. Much more than merely a new approach to storage or data management, iguazio enables organizations to realize value from their data more quickly and to get to insights from that data faster to drive competitive advantage for the organization.
The Intellyx Take
If there is one hallmark of the digital era, it is this: everything is changing.
The traditional conceptualizations of storage and data pipelines are no exception. It may be tempting to look at iguazio’s approach as simply a new way of storing data, but that would be a mistake.
The fundamental essence of their approach is to abstract data from its underlying storage and to create a unified data model that enables organizations to stop worrying about where or how they are storing their data and instead focus only on the insights and the competitive value they can harvest from it.
Copyright © Intellyx LLC. iguazio is an Intellyx client. Intellyx retains full editorial control over the content of this paper.



Comments