As enterprises look to digital success stories like Google, Netflix and Amazon, they seek to bring these companies’ web scale technologies in-house in order to support the exploding real-time, fast-data requirements of their digital initiatives.
The term “fast data” is a relatively new addition to the big data lexicon, as organizations realize that the velocity of data is just as important as the volume of information.
Fast data solutions recognize that size alone – say terabytes or petabytes of data – aren’t the whole story. Instead, terabytes per hour or petabytes per day might be the more salient metric.
While web scale companies are perhaps the most visible use cases for fast data today, there are many enterprise fast data applications as well, including real-time stock trading, real-time online advertising arbitrage, and real-time customer engagement applications that report on live inventory levels, for example. Furthermore, as the Internet of Things continues to grow, it will drive an entire new category of fast data applications as well.
Fortunately, the open source movement has taken many of the lessons learned at web scale firms and built a number of high performance, highly scalable tools for dealing with real-time, data-centric applications, including Kafka distributed messaging system, Spark cluster computing engine, and the tools in the Hadoop big data framework family, to name a few.
These technologies represent the cutting edge of today’s knowledge of how to build systems at scale. Furthermore, if enterprises want to get with the fast data program, there are in reality no true alternatives available today other than assembling solutions with these rapidly maturing tools.
The Challenge of Fast Data Applications
As the diverse list of technologies above would suggest, real-time, data-centric applications are inherently complicated. Data must continually be in motion, from multiple data sources through message brokers, stream processors, and a variety of data ‘sinks’ that both store data and make them available for numerous applications to access – all in real-time.
Dealing with such fire hoses of information requires a new way of thinking about the necessary infrastructure to assemble such data pipelines from heterogeneous components. In fact, even the word “pipeline” is misleading, as it suggests a linear flow.
In reality, however, every component of a data pipeline must scale horizontally to avoid a bottleneck, or worse, a single point of failure. As a result, data pipelines have complex topologies that are specific to their respective purposes.
Complicating matters further is the fact that the components of a data pipeline are highly interdependent, as each tool contains of several components and pipelines consist of several tools strung together.
As a result, managing such pipelines is a unique challenge, quite different from traditional IT Operations Monitoring (ITOM). Most web scale tools include their own monitoring dashboards, of course, but a single production pipeline might leverage half a dozen such tools – a recipe for confusion.
Identifying possible issues, discovering their root causes, and addressing them quickly, therefore, is a difficult challenge even for shops that run all of the separate tools’ monitoring dashboards. Furthermore, most ITOM tools on the market do not address the specific capabilities and requirements of web scale, fast data environments.
OpsClarity: Monitoring Specially Designed for Web Scale Data Pipelines
OpsClarity fills this significant and growing gap in the ITOM marketplace. With OpsClarity, it’s possible to analyze concerns across each data pipeline, including latency, throughput, error rate, and any data loss due to a problem in one of the components in the pipeline.
OpsClarity’s intelligent monitoring solution combines in-depth metrics specific to the architectures of web-scale tools. It also provides end-to-end visibility and troubleshooting capabilities that can cluster and correlate events. Furthermore, the solution requires minimal configuration, as it auto-discovers and configures each service and corresponding dashboards to the particular environment.
One of OpsClarity’s important differentiators is its ability to collect relevant metadata along with real-time metrics – metadata that are specific to the particular topology that OpsClarity is monitoring. Furthermore, OpsClarity is able to auto-detect this topology, allowing for auto-configuration of the monitoring solution.
This ability to auto-detect the specific topology of the pipeline is a critically important differentiator for OpsClarity. To understand why this capability is so significant, let’s look at what’s involved in monitoring just one of these tools, Apache Kafka.
Kafka consists of a number of individual brokers sandwiched between a set of producers and a set of consumers. The number of each of these components is subject to change based upon capacity requirements, and as a result, the message traffic flows among the components are inherently dynamic.
OpsClarity understands the complex, specific topology considerations for Kafka (as well as other fast data tools), and is thus able to monitor metadata for each of the separate components, as well as metrics that are relevant for those components.
OpsClarity currently manages an extensive list of supported services, and it is adding more all the time.
Monitoring the Entire Pipeline
Unlike other applications that monitor individual tools, OpsClarity is able to provide critically important visibility across the entire data pipeline. It understands the topology of each pipeline, and thus is able to report on the health of individual services as well as overall concerns like throughput, error rates, and latency.
OpsClarity leverages a high performance streaming analytics engine for several of the fast data technologies it is able to monitor, in order to collect, analyze, and store large quantities of data.
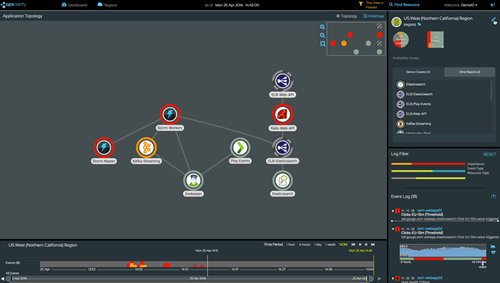
Topology Driven Troubleshooting (Source: OpsClarity)
On top of the analytics engine are OpsClarity’s operations analytics technologies, including automated topology discovery and anomaly detection as shown in the screenshot above, as well as automated health synthesis. Based on these technologies, OpsClarity offers large-scale data visualization for rapid correlation of events.
The Intellyx Take
Many ITOM tools try to be all things to all people, and as a result, have weaknesses that ops personnel must work around. In contrast, OpsClarity specializes in monitoring web scale, fast data environments that are becoming an increasingly critical part of the enterprise infrastructure.
For IT shops used to dealing with legacy application infrastructure and inflexible middleware, dealing with web scale technologies can be both a relief and a challenge.
Such technologies certainly offer broad-based benefits to organizations as they reinvent themselves as data-driven digital enterprises. But on the downside, these new technologies require new architectures, new tooling, and above all, new ways of thinking about IT infrastructure.
OpsClarity is well-positioned to ride this wave. By focusing on the unique monitoring challenges of today’s rapidly maturing fast data technologies, OpsClarity fills a valuable niche for any organization looking to take advantage of these modern approaches to IT infrastructure.
Copyright © Intellyx LLC. OpsClarity is an Intellyx client. None of the other organizations mentioned in this article are Intellyx clients. Intellyx retains full editorial control over the content of this article.


