Configuration drift refers to the phenomenon of how the configurations of individual IT infrastructure components can change over time, gradually losing alignment with each other or with the original business intent.
Configuration drift can happen to any component anywhere in the environment – network components, servers, virtual machines (VMs), or other compute components, storage components, applications, etc.
While individual components can experience such drift, a more significant type of configuration drift occurs when sets of components that operators provisioned in order to assure policy, security, and compliance best practices of the organization lose alignment with those practices.
In many cases, the cause of configuration drift is manual intervention when an operator or someone else makes changes to individual components, perhaps without proper governance or planning in place. This can be a common occurrence in organizations with multiple teams managing the infrastructure, such as where a global team manages the backbone network and sets best practices while local teams run the regional networks.
Configuration drift can also occur on its own with no human involvement. Configurations, after all, aren’t always static. They often depend upon formulas that leverage other configurations or telemetry data, which themselves might change over time.
Today, configuration drift remains a challenge as enterprise IT infrastructures undergo a paradigm shift. Organizations are implementing cloud-native applications with microservices-based architectures that often depend on even more connections (which are integral to the application’s function) than virtualized workloads.
These factors increase the need for intent-based automation as the next-generation remediation approach to configuration drift.
Understanding the Problem of Configuration Drift
Figure 1 below illustrates how operators mitigated the problem of configuration drift in the past.
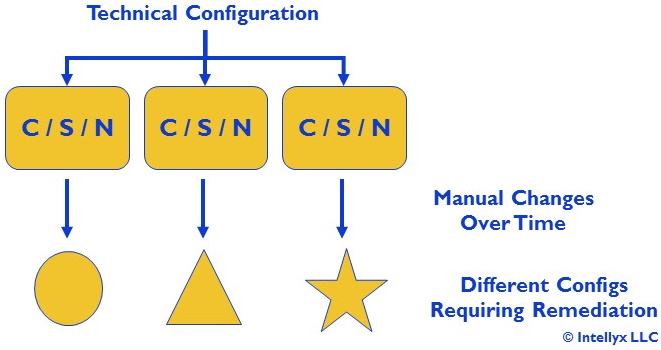
Figure 1: Manual Remediation of Configuration Drift
In this illustration, there are three instances consisting of compute, storage and/or network components (C, S and N, respectively) representing some set of components that are supposed to have largely identical configurations.
However, given a number of manual changes to each component over time, the result is that the components are no longer in sync (represented by the different shapes). This misalignment could introduce risks to the organization in the form of disruptions to service-level delivery and/or vulnerability to security attacks.
In the absence of automated remediation, operators in this example must first identify where drift has occurred and then manually reconfigure some (or all) of the components, both to be in alignment with business requirements, as well as to keep the components in sync with each other – a time-consuming, error-prone, and difficult-to-scale task.
The Infrastructure-as-Code Approach
Another approach is to represent the desired configurations of all the components, including the processes that operators must follow to implement those configurations in practice, as a set of configuration metadata. This infrastructure-as-code (IaC) approach is shown in Figure 2 below.
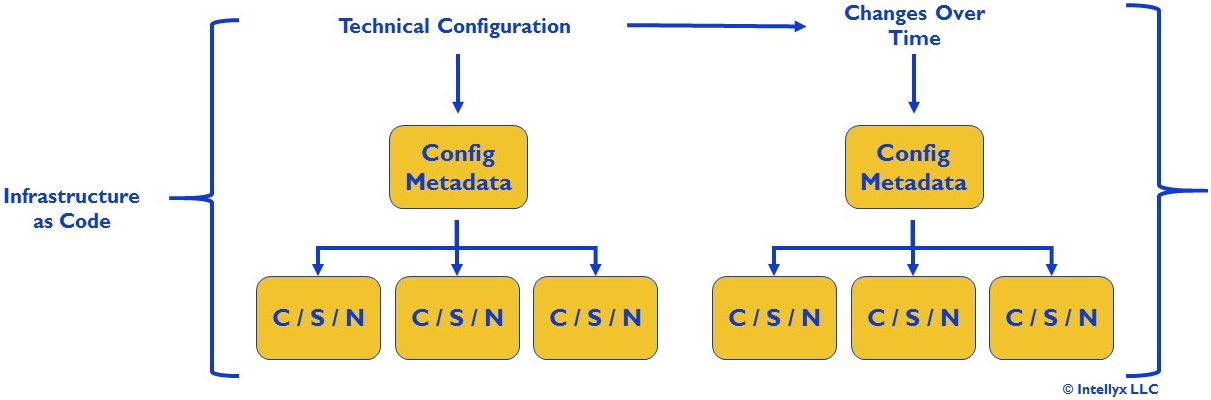
Figure 2: Infrastructure as Code
With IaC, if a problem arises in one of the production components (for example, a misconfiguration), the operators revert or redeploy using the configuration they’ve specified in the configuration metadata.
IaC is particularly useful when dealing with large numbers of fragile nodes, as would be the case in a scaled-out cloud computing environment. In cloud-native architectures, organizations expect individual nodes to fail, so IaC is the best approach to ensure resiliency of large numbers of nodes working in concert.
IaC is less useful, however, in high-availability environments in which individual components are expected to be durable and taking them offline to reconfigure them would be problematic—for example, when the nodes consist of physical network elements.
Kubernetes: Pushing the Limits of Infrastructure-as-Code
Since Kubernetes is fundamentally a declarative, configuration-based platform, it should come as no surprise that IaC is de rigueur for keeping Kubernetes configurations up to date.
IaC, however, does not scale well enough to handle Kubernetes configurations at scale. While IaC is adequate for individual clusters, configuration drift can nevertheless rear its ugly head in multicluster scenarios, as Figure 3 below illustrates.
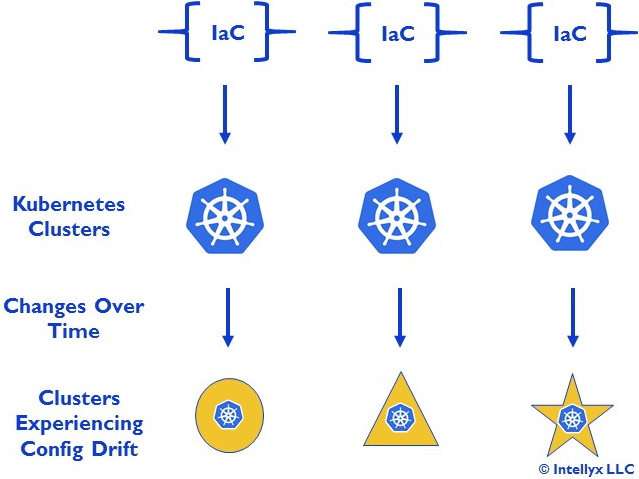
Figure 3: Configuration Drift in Multicluster Kubernetes Scenarios
This example uses the IaC approach for each cluster. (Assume Figure 2 appears in each IaC bracket.) IaC is an integral part of how Kubernetes maintains containers and pods within each cluster, but the clusters themselves can easily experience drift, especially when different teams are using separate clusters.
Intent-Based Automation to the Rescue
The solution to the above types of configuration drift – even across Kubernetes clusters – is intent-based automation. An extension of the intent-based networking approach that products like Juniper Apstra are based on, intent-based automation solutions:
- Use the business intent for the infrastructure as input, translating it to a technical configuration they can represent as metadata
- Enforce the resulting technical configurations across the desired infrastructure
- Continually ensure that the configured components remain in alignment with business intent via “closed-loop” automation.
The latter, of course, is how Intent-based automation deals with configuration drift, as shown in Figure 4 below.
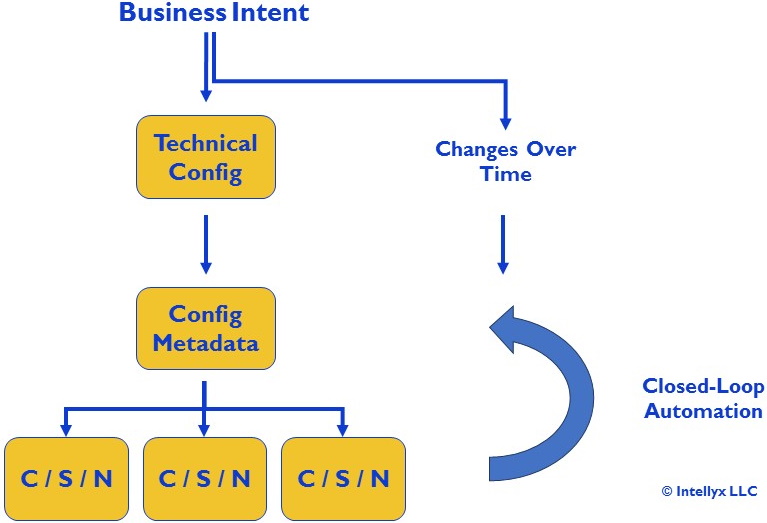
Figure 4: Intent-Based Automation
In this figure, the intent-based automation solution translates the business intent into the configuration metadata necessary to automatically configure the infrastructure components in question. Those components might be network devices in the instance of intent-based networking, but they can also be servers, VMs or Kubernetes clusters.
The intent-based automation solution continually monitors the actual configurations of the components in the production environment, ensuring they remain in alignment with the business intent – even in those situations in which that intent changes over time.
The Intellyx Take
The most powerful aspect of the intent-based automation approach in Figure 4 is that it is a simple representation that can apply at any level of scale, from a single router to hundreds of Kubernetes clusters.
Unlike IaC that runs into limitations as scale and agility requirements mount, intent-based automation automatically supports such requirements, even when the configurations become too complex for human operators to keep up with.
In fact, without the closed-loop automation of intent-based automation, there would certainly be no hope of achieving the levels of scale and agility that are the fundamental promise of cloud-based computing for enterprise IT, edge computing, or anywhere else.
Copyright © Intellyx LLC. Juniper Networks is an Intellyx client. Intellyx retains final editorial control of this article.


