Had Mark Twain lived today, we might hear him utter the oath lies, damn lies, and analytics. Statistics to be sure may still be used to distort the truth – but now with the sudden explosion of big data, analytics threaten the same fate.
I’m not talking about intentional distortion here – that’s another story entirely. Rather, the risk of unintentional distortion via data analytics is becoming increasingly prevalent, as the sheer quantity of data increases, as well as the availability and usability of the analytics tools on the market.
The data scientists themselves aren’t the problem. In fact, the more qualified data scientists we have, the better. But there aren’t enough of these rare professionals to go around.
Furthermore, the ease of use and availability of increasingly mature analytics and other business intelligence (BI) tools are opening up the world of “hands on” analytics to an increasingly broad business audience – few of whom have any particular training in data science.
Are today’s BI tools to blame for this problem? Not really – after all, the tools are unquestionably getting better and better. The root of the problem is data preparation.
After all, the smartest analytics tool in the world can only do so much with poorly organized, incomplete, or incorrect input data – the proverbial garbage-in, garbage-out problem, now compounded by the diversity of data types, levels of structure, and overall context challenges that today’s big data represent.
’Twas not always thus. Back in the good old first-generation data warehouse days, data preparation tasks were more straightforward, and the people responsible for tackling these activities did so for a living.
Now, data preparation is more diverse and challenging, and we’re asking data laypeople to do their best to shoehorn big data sets as best they can into their newfangled analytics tools. No wonder the end result can be such a mess.
A Closer Look at Data Preparation
Integrating multiple data sources, either by physically moving them or via data virtualization, typically involves data preparation. Traditional preparation tasks often include:
- Bringing basic metadata like column names and numeric value types into a consistent state, for example, by renaming columns or changing all numbers into the same kind of integer.
- Rudimentary data transformations, for example, taking a field that contains people’s full names and splitting them into first name and last name fields.
- Making sure missing values are handled consistently. Is a missing value the same as an empty string, or perhaps the dreaded NULL?
- Routine aggregation tasks, like counting all the records in a particular ZIP Code and entering the total into a separate field.
So far so good – while a data expert will have no problems with these tasks, many an Excel-savvy business analyst can tackle them without distorting results as well.
However, when big data enter the picture, data preparation becomes more complicated, as the variety of data structure and the volume of information increase. Additional data preparation activities may now include:
- Data wrangling – the manual conversion of data from one raw form to another, especially when the data aren’t in a tabular format. What do you do if your source data contain, say, video files, Word documents, and Twitter streams, all mixed together?
- Semantic processing – extracting entities from textual data, for example, identifying people and place names. Semantic processing may also include the resolution of ambiguities, for example, recognizing whether “Paris Hilton” is a socialite or a hotel.
- Mathematical processing – yes, even statistics may be useful here. There are numerous mathematical approaches for identifying clusters or other patterns in information that will help with further analysis.
It’s important to note that the challenge with these more advanced data preparation techniques isn’t simply that inexperienced people won’t be able to perform them. The worry is that they will think they are properly preparing the data, when it fact they are doing it wrong. The end result will hopefully be obviously incorrect, but an even more dangerous scenario is when the final analysis seems correct but in reality is not.
Addressing Data Preparation Challenges
A common knee-jerk reaction to the scenarios described above is simply to establish rules to prevent unqualified users from monkeying with data preparation tasks in the first place. However, such draconian data governance measures typically have no place in a modern data-centric business environment.
The better approach is to provide additional data preparation and data integration tooling that data professionals may configure, but business analysts and other business users may use to prepare data for themselves. In other words, establish a governed, self-service model for data preparation.
For example, data professionals can preconfigure the reusable Snaps from SnapLogic so that they can handle the messier details of data preparation, as well as data access and other transformation tasks. The broader audience of users can then assemble data pipelines simply by snapping together the Snaps. See the illustration below for a SnapLogic pipeline that these “citizen integrators” can create to combine data.
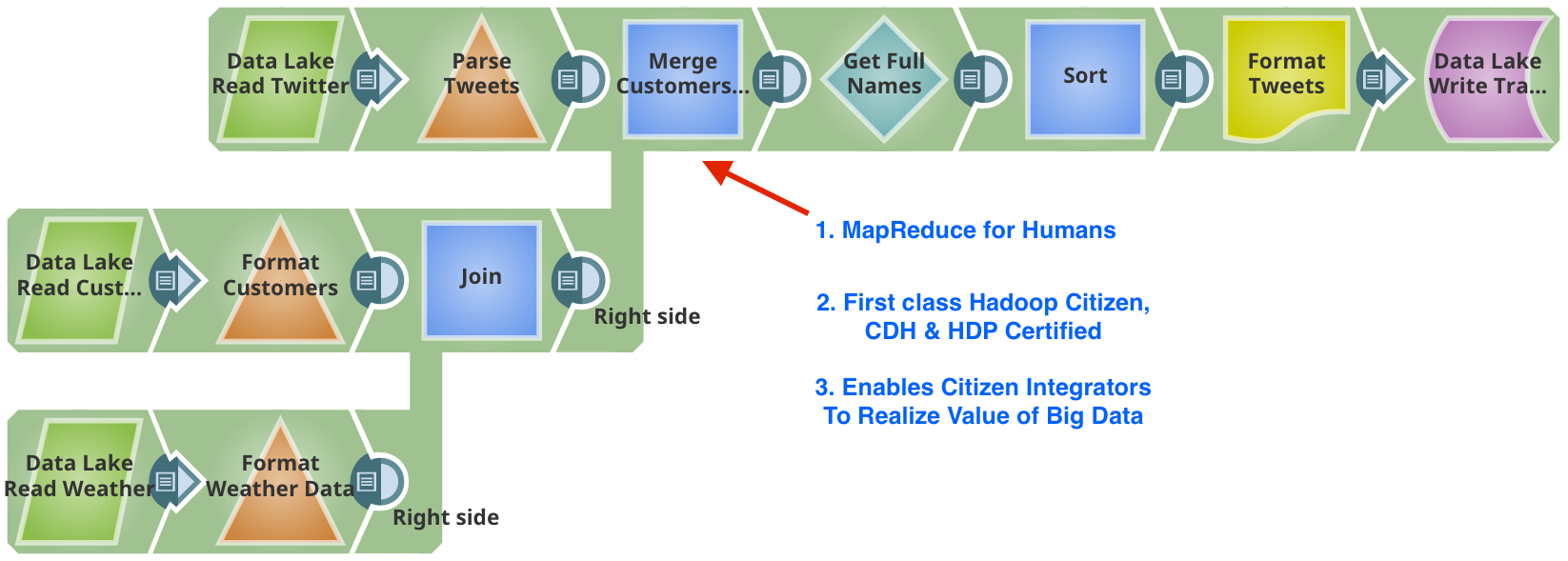 SnapLogic Pipeline (source: SnapLogic)
SnapLogic Pipeline (source: SnapLogic)
It’s also possible to create nested sub-pipelines, so that business users assemble pre-assembled and preconfigured sub-pipelines as well as Snaps into larger data integration pipelines. Such pipelines can be made up of many levels of nested sub-pipelines, and SnapLogic can guarantee the delivery of data from each sub-pipeline (much the same as traditional queues offer guaranteed delivery, extended to many other types of Snaps).
SnapLogic also offers a sub-pipeline review, allowing both experts and business users to see the processing steps within each sub-pipeline, as well as relevant data governance capabilities that support this self-service data preparation approach. For example, it offers a lifecycle management feature that allows for the comparison and testing of Snaps and sub-pipelines before business users get their hands on them.
The Intellyx Take
In the case of SnapLogic, it falls to the data integration layer to resolve the challenges with data preparation. In truth, SnapLogic is essentially a data integration tooling vendor – but there is an important lesson here: data preparation is in reality an aspect of data integration, and in fact, data governance is part of the data integration story as well.
As enterprises leverage big data across their organizations, it becomes increasingly important to support the full breadth of personnel who will be working with such information, in order to get the best results from the resulting analysis. Leveraging data preparation capabilities like those found in SnapLogic’s pipelines is a critical enabler of useful, accurate data analysis.
SnapLogic is an Intellyx client, but Intellyx retains full editorial control of this article.



I’ve always held to the other form of GIGO – Garbage in, Gospel out. There’s always been too much trust in well-formatted or well-presented data. As a complement to the pipelines, I wonder if there’s a presentation tool that can identify when the information being displayed originates from ‘smelly’ sources.