For organizations with applications still residing on-premises, as well as those companies with applications in the cloud, the promise of Kubernetes beckons.
While scalability on traditional virtual machines (VMs) is a plodding affair, Kubernetes offers fast, seamless scale-out of running services – as well as the benefits that increasingly modular development brings to scaling up the teams that build them.
However, while ‘lifting and shifting’ applications to the cloud is relatively straightforward – VMs looking and working much like physical servers do, after all – Kubernetes is a different matter.
Kubernetes brings containers, pods, and clusters to the table, as well as broad, universal abstractions and a fully configuration-driven approach to deployment and change management, thus sending discussions of Kubernetes deep into the weeds.
Implementing a coherent logical abstraction that simplifies maddeningly complex technical details that make it a reality is a challenge that a few vendors are seeking to bridge – and Robin is one of them.
Example: A ‘Simple’ Three-Tier Application
What, then, do we mean by a ‘coherent logical abstraction’? Perhaps an example will help. Let’s take a look at a simple three-tier application, as shown in figure 1 below.
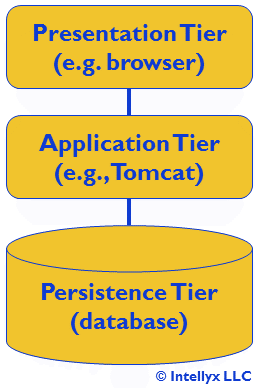
Figure 1: A Simple Three-Tier App (Logical View)
Logical views like the one above intentionally hide a multitude of technical details from view. In this case, we take the network for granted, even though it would contain a load balancer between the presentation and application tiers that direct traffic to multiple instances of the application, typically running on separate VMs.
Even when the three-tier app runs in the cloud, it faces some fundamental limitations. Scaling up requires provisioning of additional VMs, which is often too slow to respond to sudden changes in demand, and can also be expensive to provision and maintain.
It is also difficult to scale up the team responsible for maintaining and updating the application, as it is increasingly difficult to for members of a large team to work in parallel as the size of the application grows.
Migrating the Application to Kubernetes
Cloud-native architecture – the core best practices for architecting Kubernetes-based applications – adds additional layers of abstraction to mask additional depths of complexity. As such, while our three-tier app still essentially maintains its three logical tiers, the logical representation of the app looks quite different after we migrate it to Kubernetes, as figure 2 below illustrates.
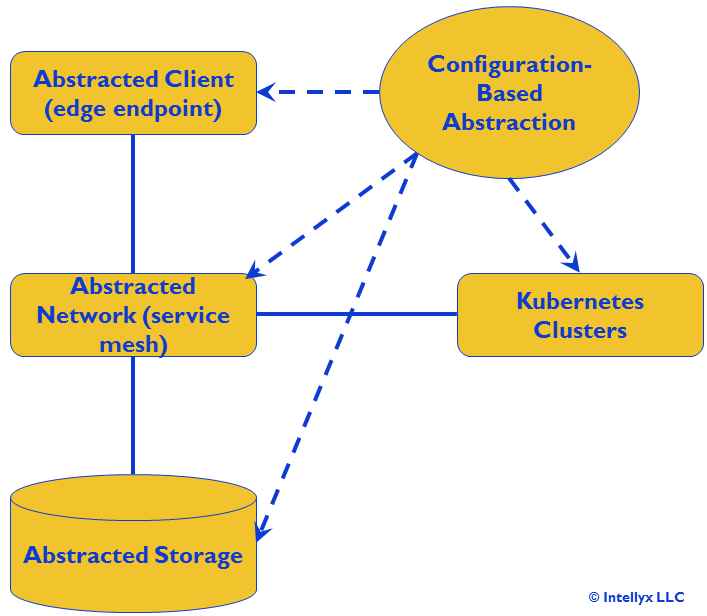
Figure 2: Logical View of Kubernetes Application
In the figure above, we’ve extended our browser-centric presentation tier to an abstracted client that allows for any edge endpoint, including mobile devices, IoT endpoints, cloud endpoints for third-party SaaS apps, etc.
Similarly, we’ve replaced our traditional persistence tier with abstracted storage, and our Kubernetes clusters now represent the application tier.
However, while our three-tier logical architecture takes the network for granted, in the Kubernetes architecture it is a first-class citizen, as the configuration drives the abstraction across compute, network, and storage in a coherent manner.
A service mesh handles ‘east-west’ microservice interactions within the Kubernetes clusters via this comprehensive abstraction that isolates physical network characteristics like VLANs and IP addresses from the logical network.
Cloud-native API management technology deals with the ‘north-south’ interactions between clients and microservices in the clusters, and abstracted storage interfaces (with technologies like Container Storage Interface (CSI) plugins and persistentVolumes).
Coordinating all these complex, interconnected behaviors of the various components of deployed implementations of cloud-native architecture at scale is an end-to-end configuration-based abstraction.
In other words, all aspects of the production deployment should be represented via configuration (in Helm charts, YAML files, etc.). To make any change in production, the Kubernetes team should change the configuration and redeploy as necessary, following the ‘cattle not pets’ principle of immutable infrastructure.
Abstracting the ‘Lift and Shift’
The most important conclusion you should derive from the discussion above is that migrating an app that looks like figure 1 into Kubernetes so that it ends up looking like figure 2 is by no means straightforward. Even when the original app is a fully modern, cloud-based app, such migration is far from elementary – and when the app is less than modern, all bets are off.
This situation is one of the knottier challenges that Robin addresses. Robin essentially provides an additional layer of abstraction, enabling an application to migrate from figure 1 to figure 2 without the complex, onerous rearchitecting and rewriting that applications would normally require.
Furthermore, Robin addresses the particular needs of each tier, in particular, the persistence tier that must now leverage abstracted storage. The challenge at this tier is that Kubernetes is essentially stateless, and thus all aspects of the architecture in figure 2 aren’t expected to keep track of either the state of any application or its data.
Remember, Kubernetes containers (as well as pods and even clusters) are essentially ephemeral, so if they keep track of anything, that state information can easily and suddenly be lost.
Robin handles all the resulting state management issues on behalf of the migrated application, handling the interactions with the abstracted storage while taking care of knottier state-related issues like rollbacks and disaster recovery.
Furthermore, Robin can even maintain application state as well – a challenge that Kubernetes itself offers no way of handling. For example, if a process (say, an ecommerce purchase) fails midstream, Robin can maintain the state of the application as Kubernetes reprovisions the failed components on the fly.
The Intellyx Take
For simplicity’s sake, the discussion above focuses on a single application. In the real world, however, enterprises are lifting and shifting multiple applications at once to Kubernetes.
As a result, there’s more to this story. Organizations must not only shift individual apps, but also string together multiple applications into ‘application pipelines’– orchestrated combinations of applications that companies update frequently to respond to ongoing changes in the marketplace.
Cloud-native architectures that support such dynamic pipelines are inherently different from architectural approaches that came before, even though they necessarily build on the lessons of the past.
To succeed with them – and with Kubernetes in general – it’s essential to think outside the box, where that box is everything you thought you knew about architecting enterprise application infrastructure at scale.
© Intellyx LLC. Robin is an Intellyx customer. Intellyx retains final editorial control of this article.
See Jason Bloomberg present on the webinar Designing A Cloud-Native Roadmap for Enterprise Applications with Simone Sassoli, Chief Customer Officer of Robin.io, January 23 at 10:00 PST/1:00 EST. Click here for more information and to register.


