Data lakes are among the hottest topics in the enterprise big data world today. While data warehouses have provided value for many years, they require careful preparation and formatting of data before loading it into the warehouse. With data lakes, in contrast, people can load all types and structures of data first, in the hopes that someone will be able to get value by transforming and analyzing the data at some point in the future.
Data lakes are becoming increasingly essential to today’s enterprise digital strategies, so EAs should understand their strengths and weaknesses, and how to facilitate their proper adoption across the organization.
A useful and concise resource for understanding data lakes is the white paper How to Build an Enterprise Data Lake: Important Considerations Before Jumping In, by Mark Madsen of Third Nature.
In this paper, Madsen first defines a naïve approach to data lakes: collecting and storing data in its original format in Hadoop, and then letting analysts make sense of it later. However, he points out, this approach is ineffective because it doesn’t scale organizationally.
Essentially, this naïve approach assumes that people have the skills they need to find and process data – an assumption that becomes increasingly tenuous as an organization proceeds with their digital initiative.
Madsen also distinguishes between different purposes for data. Some people need to perform one-off analyses, while in other cases, someone wants to set up an automated process for interacting with or consuming data. Furthermore, different data-centric processes have different priorities and management requirements.
All of these concerns reflect and reinforce the organizational changes that enterprises are navigating today. Gone are the days were data processing was entirely an IT function, and IT acted as a gatekeeper, limiting and controlling access to data from lines of business.
Today, enterprises are gradually realizing that such an inflexible, bimodal pattern for IT is counterproductive. IT must still support the data needs of the business, but instead of acting as a gatekeeper, it must take the role of an enabler of self-service capabilities.
Without the guidance of the EAs, however, the data architects responsible for planning and coordinating the data lake initiative may not have the proper scope and context to drive the appropriate self-service access to the data lake.
Architecting a Data Lake
Madsen has specific advice for data architects as they plan their data lakes. He recommends separating the architecture into four areas: a storage area for acquiring and collecting data, an area for standardizing some data sets, a third area for structuring some data for specific uses, and a working area for transient data, as shown in the figure below.
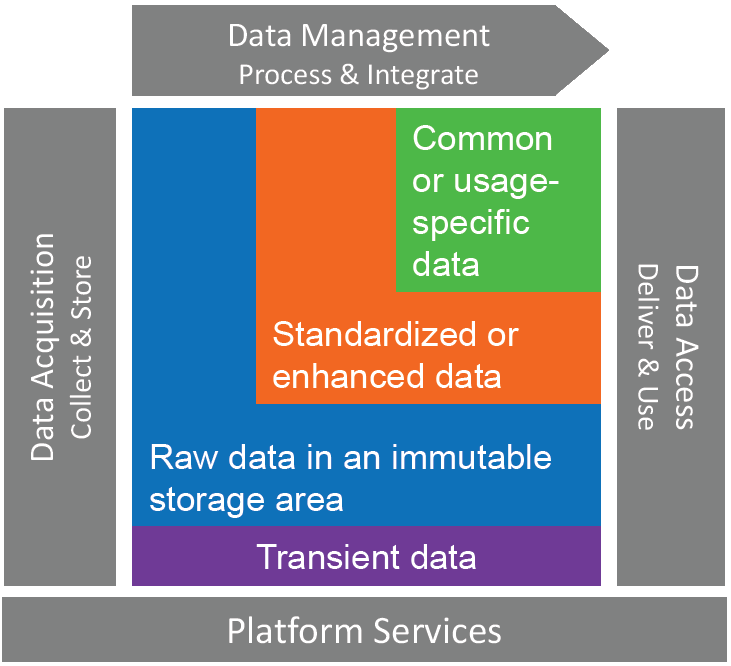
Data Lake Architecture (Source: Third Nature)
The storage area should contain immutable data, while the standardization and structuring areas are specific to particular purposes, and different people will use the data in these areas in different ways, depending upon their goals, but also upon their role and the business context of their data usage.
Without the appropriate governance – not the gatekeeper governance of old, but the empowerment-driven governance of today – people are likely to misuse the different areas, depending upon their skill set with the data architecture.
Furthermore, the fact that some data must be standardized or structured suggests that someone must be responsible for the curation of data. Think of the role of a librarian – not only responsible for organizing information, but also interacting with the people who wish to consume information, helping them to obtain the right information for their needs.
In fact, curation is especially important in a self-service environment. In fact, Madsen calls self-service analysis a “myth” in the absence of a curated environment.
As an organization’s deployment of the data lake matures, more people will find themselves in the role of data curator. Sometimes these people will be data professionals within the IT organization, but to an increasing extent, data curators will be line of business personnel, focused more on the business value of the information than the technical considerations surrounding data structure and semantics.
In some cases, EAs may serve as curators, but more broadly speaking, EAs should consider the organizational and process implications of an expanding and diverse team of curators – once again working to empower self-service, while also establishing the appropriate guidelines to ensure the resulting information is complete and unbiased, as well as properly secure and respectful of privacy considerations.
Raising the Bar on Metadata
As I’ve written about before, one of the primary challenges with data lakes is the risk of losing track of the metadata necessary to guarantee data in the lake can continue to provide value. Just as a bucket of water poured into a real lake loses its identity, data may suffer the same fate – if their metadata aren’t properly managed and governed.
Madsen agrees. He points out that data lakes must keep track of schemas implicit in each data set or those data will become impossible to find over time. Furthermore, he calls for the capture of usage metadata, so that it’s possible to track the usage of the data lake over time.
This usage information is important for many reasons. Tracking cross-organizational usage of data maintains both data lineage and provenance. Furthermore, for sensitive information, usage tracking is essential for ensuring privacy.
Note that the advice to track data usage actually calls for the ongoing creation of additional metadata after data are put into the data lake – and furthermore, usage metadata will also apply to the original metadata. This ‘meta-metadata’ requires special architectural care from EAs, as confusion might easily result from such information, especially in the context of self-service data consumption.
The Intellyx Take
One of the most important roles of the EA in the context of the modern digital enterprise is steering the organization around the twin hazards of shadow and bimodal IT. Unfortunately, for many organizations still struggling with these issues, the risk of a ‘shadow’ data lake is very real.
If lines of business regard IT as too slow to meet their needs, they may take the questionable step of putting together their own data lake, separate from any official data efforts out of the IT department. This separation, however, is a recipe for disaster.
EAs must be proactive to avoid such a fate. The EA’s role has always been to maintain an end-to-end perspective on the organization, and how it leverages technology to meet business needs. With the rise of digital transformation, this end-to-end perspective is especially critical, and EAs should apply that perspective to their organization’s data lake initiatives.
SnapLogic is an Intellyx client. At the time of writing, no other organizations mentioned in this article are Intellyx clients. Intellyx retains full editorial control over the content of this article.



Thanks for reviewing the paper Jason. Great insights as always. Your readers may also be interested in the webinar recording and slides Mark Madsen presented on the topic. The links are available on the SnapLogic blog here: http://www.snaplogic.com/blog/all-about-the-data-lake/